Crawlers, also known as spiders or bots, are programs used by search engines to explore the internet, collecting and indexing data along the way.
When a crawler encounters a hyperlink, it visits the site linked by that URL. It reads the site’s content and examines the links embedded within it. The crawler then follows those links to new sites, continuing this process endlessly. This methodical journey through the web, moving from link to link, is why these programs are called crawlers. Their role is crucial in making sure every interconnected website is indexed and accessible for search engines.
Why Are Crawlers Important to SEO?
Enhancing Website Accessibility
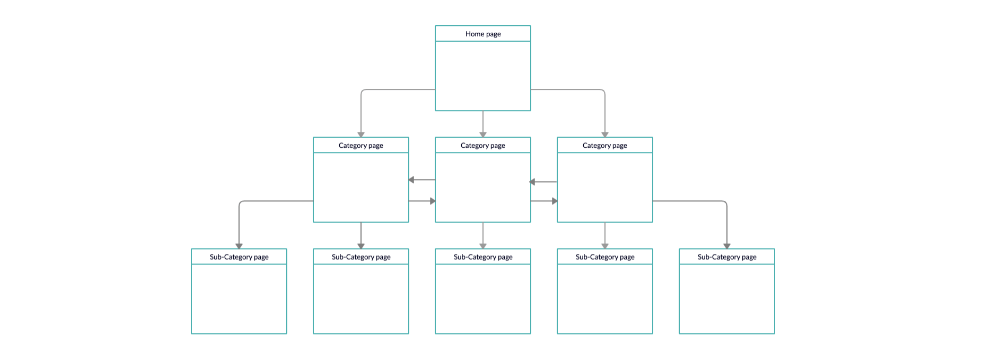
Making your website easy for crawlers to navigate significantly boosts your SEO. Sites that are simple to visit and browse, with key pages accessible within a few clicks from the homepage, become more appealing not only to crawlers but also to users. Utilizing sitemaps helps crawlers pinpoint the crucial content on your site, further aiding in this process.
Following Links and Building Authority
Crawlers trace links to and from your site, as well as the internal links within it. Having a well-structured internal link system is essential for crawlers to index all your pages. Additionally, high-quality external links, leading to and from your site, signal that your content is reputable and valuable, enhancing your site’s authority.
Indexing Content and Ensuring Uniqueness
Crawlers index the content on your site unless it’s blocked by your robots.txt file or other means. They scan for keywords to determine which search terms your page should rank for. Moreover, crawlers check for duplicate content, ensuring your website’s material is unique and not copied from other sources.
At Tomatotree Digital, we understand the intricacies of how crawlers work and how to optimize your website for them, ensuring your site stands out in search engine rankings.
Is There a Difference Between a Crawler and a Spider?
In essence, there’s no difference. The term “spider” is simply a nickname inspired by how these programs “crawl” the web. These digital explorers are also known as robots or bots.
Types of Crawlers
Crawlers come in different flavors, each serving a specific purpose:
General Web Crawlers: These are the workhorses of search engines like Google and Bing. They relentlessly explore the web, discovering new websites and indexing existing ones.
Focused Crawlers: As the name suggests, these crawlers target specific websites or topics. They might be used for market research, competitor analysis, or specific data collection purposes.
Deep Web Crawlers: The deep web refers to content not readily accessible by traditional search engines. Deep web crawlers are specially designed to navigate these hidden corners of the internet.
How Crawlers Work
Here’s a deeper look at the crawling process:
Seed URLs: Crawlers begin with a set of seed URLs, which can be manually entered or retrieved from a sitemap.
Fetching and Parsing: The crawler fetches the content of the seed URL and parses it to understand the structure and extract information.
Link Following: The crawler identifies hyperlinks within the content and adds them to a queue for further exploration.
Prioritization and Scheduling: Crawlers prioritize URLs based on various factors like freshness, relevance, and importance. They schedule revisits for frequently updated websites.
Data Extraction and Indexing: Extracted data from the webpage, including text, images, and metadata, is stored in a searchable index.
Benefits of Crawlers Beyond SEO
Crawlers have applications beyond search engine optimization. They play a role in:
Price Comparison: Crawlers can be used to gather pricing data from various online retailers, helping users find the best deals.
Market Research: Businesses can leverage crawlers to collect customer sentiment and analyze competitor strategies.
Data Aggregation: Crawlers can be employed to gather specific data sets from across the web for research or analysis purposes.
The Future of Crawling
As the web continues to evolve, so too will crawling techniques. We can expect advancements in:
Machine Learning: Machine learning algorithms can help crawlers better understand the content and context of webpages, leading to more efficient and accurate indexing.
Real-time Crawling: Crawlers may become more adept at handling dynamic content and real-time updates.
By understanding crawlers and their role in the digital ecosystem, you can leverage their power for various purposes, not just limited to SEO.
Got more questions about crawlers? Feel free to reach out. At Tomatotree Digital, our expertise in technical SEO can help elevate your search marketing to new heights. Join us to discover how we can elevate your online presence together.
Additional Information
Moz:
The Beginner’s Guide to SEO: This article by Moz, a reputable SEO software company, briefly explains how crawlers work in the context of SEO.
How Search Works : While not directly about crawlers, this page from Google explains how search works, which heavily relies on crawling and indexing.
Get Better Online Visibility and Dominate the Search results
Choose TomatoTree Digital, Kerala’s Affordable SEO Company, for personalized strategies that deliver real results. Get in touch today and take your brand to new heights!